

layer가 깊으면서 현재 가장 많이 쓰이는 ResNet을 알아보자.
Introduction
오늘 리뷰 할 논문은 K. He가 마이크로소프트에 있을 때 발표한 ResNet의 첫 번째 논문이다.
Convolutional Layer가 깊을수록 더 복잡하고 추상화된 고급 정보를 추출하기 때문에 학습이 잘 된다고 알고 있는데, 그럼 Layer를 쉽게 쌓는 만큼 학습이 잘 되어 좋은 성능을 보여줄까?라는 생각을 하며 실험을 진행했다.
layer가 깊으면 vanishing/exploding gradient 문제, 과적합 문제, 그리고 연산량 증가 문제 등이 있어 학습하는데 어려움이 있지만, Normalization 기법들로 gradient 문제를 해결해 어느 정도 깊이까지는 수월하게 학습이 가능하다.

근데 직접 실험을 해보니 단순히 Conv Layer를 쌓아 학습할 경우에 일정 이상의 layer를 가질 경우 [그림 1]과 같이 degradation 문제가 발생해 56-layer가 20-layer보다 에러율이 높아 정확도가 낮아지는 걸 보여준다.
degration 문제가 test error 뿐만 아니라 training error에서도 발생하는 것을 보아 과적합 문제가 아닌 layer가 깊기 때문에 발생한다는 걸 확인할 수 있다.
그래서 degration 문제를 해결하고자 논문에서는 Residual Learning 기법을 제안한다.
Residual Learning

기존 학습 방법은 [그림 2]처럼 입력 x가 layer들을 지나 H(x)를 학습하는 것인데 다음과 같이 표현할 수 있다:
H(x) = f(x)
그런데 이 식은 f(x)가 어떤 값이 될 지 몰라 매 layer마다 새로운 값을 학습해야 하기 때문에 어렵다. 그래서 [그림 3]의 학습법을 제안한다.

identity x를 short connection으로 더해주면서 식이 다음과 같이 된다:
H(x) = F(x) + x
기본 학습하는 방법과 비교했을 때 입력으로 주어진 x를 그대로 더하는 것과 같다. 그런데 잘 봐야 할 것은 F(x)는 마지막 ReLU를 더하기 전까지의 값이며, 여기다가 x를 더해 ReLU를 통과시켜 H(x) 값을 얻는다.
(여기서 ReLU를 마지막에 통과하기 때문에 후속 논문에서는 오염됐다고 판단해 activation function 위치를 옮긴다.)
x의 값은 변하지 않기 때문에 F(x)가 최소가 되도록 학습을 진행하면 되고, F(x) = H(x) - x 임으로 출력 - 입력이 되어 잔차(Residual)이라고 한다. 따라서 목표는 H(x) = x가 된다.
그리고 원래 F = W_2σ(W_1x)로 곱셈으로 인해 연산이 복잡해지는데 논문에서는 y = F(x, {W_i}) + x로 곱셈 대신 덧셈으로 식을 표현 가능하다.

그리고 Short Connection으로 x를 mapping 할 때 Down-Sampling 하는 부분에서 F(x)와 x의 차원이 맞지 않기 때문에 [그림 4]와 같이 Projection Mapping을 사용해 x의 차원을 맞혀준다. 기본식에서 W_s만 추가된 것이고 W_s는 이전 layer에서 얻을 수 있다.
Network Architectures
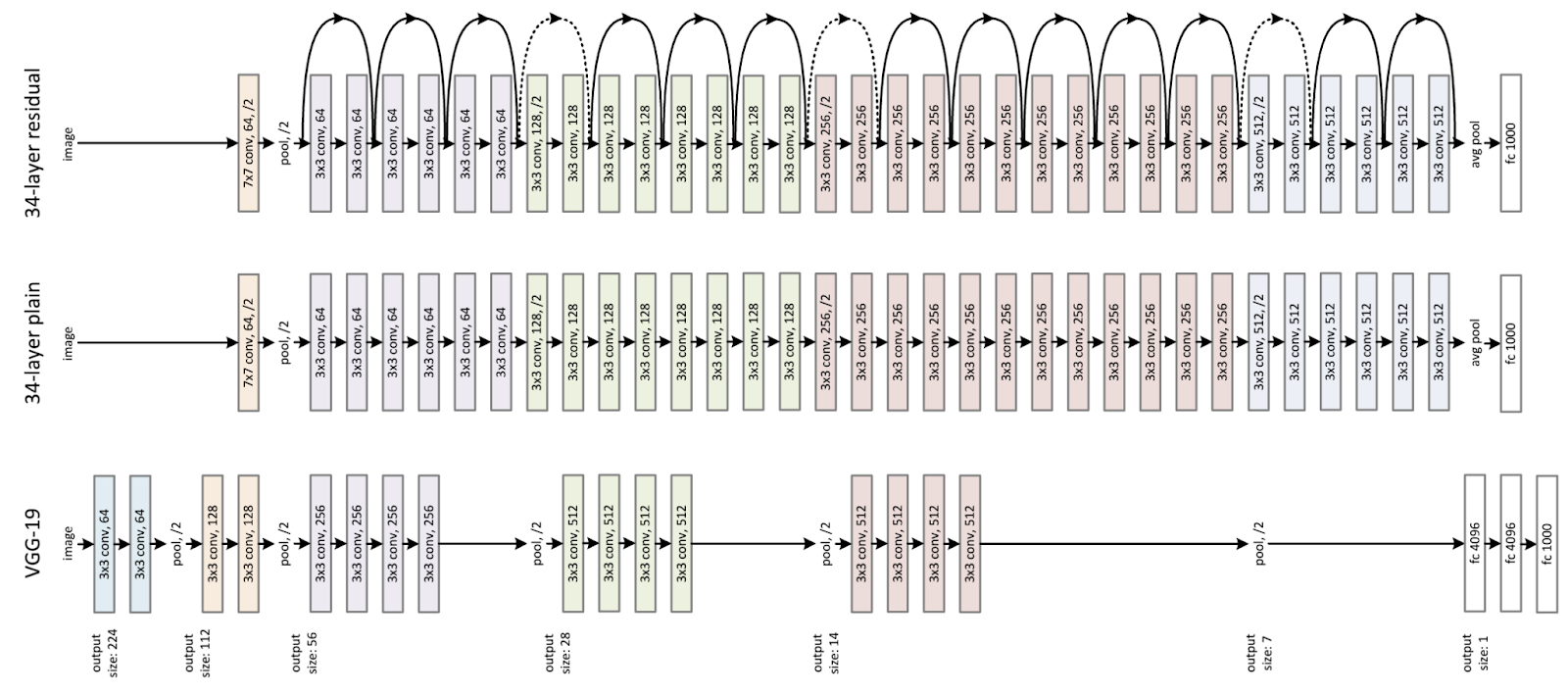
plain 모델은 VGG-19와 비슷하게 설계 되었으며, ResNet은 plain 모델에 Short Connection을 추가했다. plain 모델을 VGG-19와 비슷하게 하기 위해 두 가지 조건을 걸었는데 다음과 같다:
1) 아웃풋 사이즈가 같은 layer는 모두 동일한 필터 수를 가진다. 2) 아웃풋 사이즈가 작아 질 경우 필터를 두 배 늘린다.
Optimizer는 SGD를 사용했고 0.1 learning rate와 0.9 momentum을 사용했고 0.0001의 weight decay를 줬다. 그리고 dropout을 사용하지 않는 대신 batch normalization을 사용했다. 또한, 마지막에 global average pooling을 한 번 사용했고 conv layer에서는 ReLU를, fc-layer에서는 softmax를 사용했다.
데이터셋에 대해서는 standard color augmentation, horizontal flip을 적용했고 이미지에서 짧은 쪽을 랜덤으로 resize 한 다음에 244x244으로 random crop을 적용해 학습했다.

ImageNet에서 사용한 ResNet 네트워크 구조는 [그림 6]과 같은데 34-layer 이하랑 50-layer 이상에서 구조가 다른 걸 확인할 수 있다. 왜냐하면 50-layer 이상부터는 일반 Building Block을 사용한 것이 아니라 학습 저하를 막기 위해 Bottleneck Building Block을 사용했기 때문이다.

기본 Building Block을 사용하면 두 배 씩 증가하기 때문에 Bottleneck Building Block을 사용해 1x1 conv layer로 파라미터 수를 조절해가며 학습한다.

그 결과 ResNet은 ImageNet 학습 과정에서 degradation 문제가 발생하지 않아 layer가 깊을수록 학습이 잘 되는 걸 확인 할 수 있다.

그래서 ResNet은 34-layer에서 plain 모델보다 3.5% 낮은 에러율을 보여줬고 18-layer에서 에러율은 비슷하지만, 학습 파라미터 수가 ResNet이 적어 학습 속도가 빨랐다.
또한, ResNet 네트워크는 ImageNet뿐만 아니라 CIFAR-10, 그리고 Classification이 아닌 Object Detection에서도 좋은 성능을 보여줬다.
Reference
[1] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. of the CVPR, Jun. 2016, pp. 770-778.
'~2025' 카테고리의 다른 글
| [Python] 숫자 문자열과 영단어 - 2021 카카오 채용연계형 인턴십 (0) | 2022.04.18 |
|---|---|
| [Python] 백준 11282-11285번 문제, 파이썬에서 한글을 숫자 또는 문자열로 표현하기 (0) | 2022.04.18 |
| [CNN] LeNet-5 모델 구현하기 (0) | 2022.03.21 |
| [Git] Commit 메세지에 issue 연결하기 (0) | 2022.02.18 |
| [Git] git log 알아보기 (0) | 2022.02.02 |
